A Simple Strategy for Replacing SaaS Vendors
The switching cost to move between SaaS vendors has never been lower than it is today. Agentic coding tools have transformed the high-stakes gamble of replacing any given software vendor into an automatable, low effort task barely above the threshold of notice.
Once upon a time, vendor lock-in felt insurmountable—it was normal (and still is) to see legacy codebases dependent on 3rd party software implemented in the past, now deeply enmeshed with core functionality. Often, these choices were made with good intentions by someone no longer with the company, with justifications that don’t hold up to current business or technical requirements. The origin story of each of these baked-in messes is different, but what they all had in common was a challenge: rising to the level of priority to make it onto the roadmap.

In a pre-AI world, business realities meant developers were usually stuck with these suboptimal, legacy solutions except in the rare cases where the pain of financial cost or service degradation made it worth paying down technical debt. Vendor rip and replace tends to be tedious, in-the-weeds work with significant risk and complexity. Most of the time it was simply too expensive to justify the developer time, even if you could clear the technical hurdle of the planned refactor, which wasn’t always obvious.
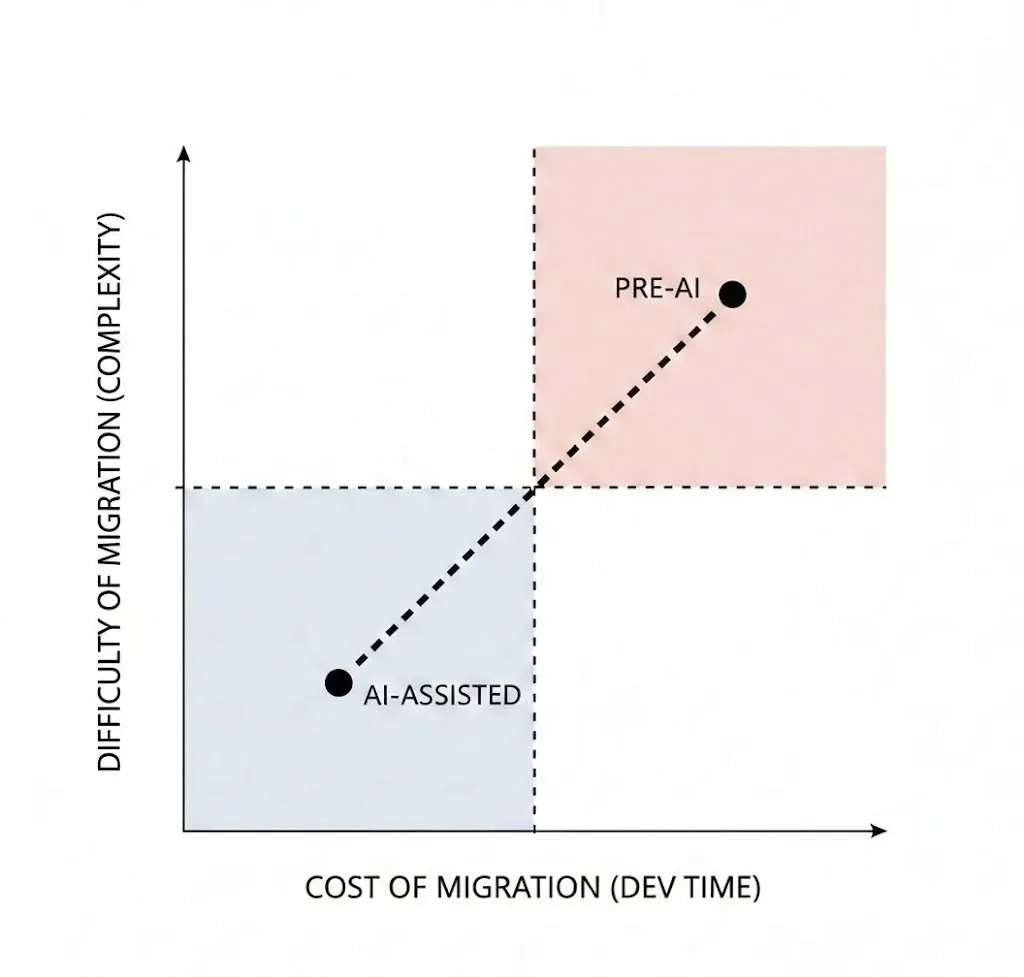
But replacing a SaaS vendor is exactly the kind of work agentic coding tools excel at. AI coding tools can streamline every step of this once-manual process, accelerating and de-risking the migration.
How we use this at Cloud Capital
At Cloud Capital, we’ve adopted this playbook to replace several SaaS vendors, including both critical systems and isolated specialty vendors (we previously wrote about one such migration, replacing our low-code platform). Regardless of scale, the approach is the same—but we recommend starting with a smaller project and applying the learnings to more ambitious rewrites.
To illustrate this workflow in action, we’ll walk through an example that likely would have felt terrifying in a pre-ai world: overhauling our authentication system.
Our customer-facing webapp is a pretty vanilla React Typescript SPA, and we previously used Clerk for our user management stack. They handled our core user models, and we leveraged their provided frontend components for user and organization authentication and account management. This was great as we were starting out and willing to make sacrifices for speed, but as our business grew and our needs evolved (and diverged from their product direction), we found that Clerk was no longer a fit for us.
Instead of living with the pain, we used our vendor rip and replace strategy to switch to a vendor we prefer, Better-Auth. Without agentic tools, the ROI on this migration wouldn’t have justified the move—but today this switch fit neatly within a single cycle, changing it from an expensive distraction to a high-value improvement.
The Agentic SaaS Vendor Rip and Replace Playbook
Scenario evaluation phase: assess the current implementation
The first step in the journey is understanding the nature and depth of the problem. Conversationally probe the codebase about the surface area affected by the target SaaS. This will inform our scoping, but also provide essential context for building our actual implementation plan.
Target output: project overview document detailed summary of the project context and current implementation. It should include technical and business shortcomings you are looking to address, the extent of the integration, desired functionality or behavior from a new solution, near-term and eventual goals. It’s also great to include a ranking of your priorities, from must-have requirements down to the quality of life niceties you could live without.
For our Auth example, this was a daunting-sounding summary — in our early days, we’d taken some shortcuts and relied on the Clerk’s React hooks directly in lots of components. This trade-off bought us critical time up front, but the cost was now coming due: hundreds of files directly importing from Clerk across the codebase, hosted Clerk components rendered on custom routes, and full reliance on their user management flows.
Research phase: vendor research and selection
Feeding the outcome of the scenario evaluation to Claude, we let the codebase itself go shopping. We described the limitations of our current vendor, our aspirations for an ideal replacement, and the long-term technical strategy. For us, important clarifications were the B2B nature of our business, a desire for deeper control of the end-user experience, strong Typescript support, and ideally open-source to give us control of our own destiny.
Target output: vendor summary list of potential replacement solutions, ranked according to the criteria we defined in the first step. This helps us trade off features, price, and other factors to narrow down our evaluation.
Auth is a crowded playing field, but given our strong desire for customization, Typescript support, and open source, Better-Auth emerged as a clear front-runner in our research. As a bonus, it allowed us to cut SaaS spend (Clerk’s Enterprise features were expensive) and replace them with better functionality for lower overall investment.
Validation Phase: feasibility assessment and migration strategy
This is the “rubber meets the road” part of the journey, and one of the areas agentic tools can be most helpful. From reading the better-auth documentation and summarizing developer feedback in the community, it sounded like a great fit. But we needed to prove to ourselves that there was a clear migration path and that it was realistic to get done quickly.
Luckily, Better Auth provides a complete migration guide for Clerk users. We asked Cursor to ingest this, review the better-auth guide, and scope a potential migration. At this point, we began evaluating the actual code-level changes and strategies to accomplish our migration while minimizing tech debt, risk, and delay.
Target output: technical design document — high-level overview of the migration strategy, including the sequence of changes, abstraction layers to introduce, rollback strategies, and a realistic scope estimate. This document becomes the blueprint for execution and helps identify risks before you’re deep in implementation.
For our auth migration, this meant mapping out how we’d introduce an abstraction layer over our authentication hooks, allowing us to swap implementations without touching every component. We identified the critical path: database schema changes, session management, and the user-facing auth flows. The design doc also surfaced edge cases we hadn’t considered, like handling in-flight sessions during the cutover.

Validation phase: minimal proof of concept
Before committing to a full migration, we de-risk the project with a minimal proof of concept. The goal isn’t to build the final solution—it’s to validate that the new vendor actually works in your environment and that your migration strategy is sound.
Spin up a branch and ask your agent to implement the most critical integration point. For auth, this was standing up Better-Auth in our development environment, connecting it to our database, and successfully authenticating a test user. This exercise surfaces integration issues, documentation gaps, and unexpected complexity before you’ve invested significant effort.
Target output: working prototype branch — a throwaway branch demonstrating the core integration works. This doesn’t need to be production-ready; it needs to prove the path is viable. Document any surprises or deviations from the plan.
Our proof of concept took less than a day. We discovered a few quirks in Better-Auth’s organization model that required minor adjustments to our data model, but nothing that changed our overall strategy. More importantly, we confirmed that the migration guide was accurate and that our abstraction approach would work.
Implementation phase: incremental migration
With validation complete, implementation becomes a matter of execution rather than discovery. The key principle here is incremental progress with continuous verification—never let the codebase get into a broken state for long.
We break the migration into discrete, deployable chunks. Each chunk should leave the application fully functional, even if some features are temporarily running on the old system. This approach lets you ship incremental progress, catch regressions early, and maintain the option to pause or roll back if priorities shift.
Target output: series of pull requests — each PR represents a self-contained step in the migration. Common stages include: introducing abstraction layers, migrating data models, swapping backend integrations, updating frontend components, and finally removing legacy code.
For our Clerk migration, this looked like:
- Abstraction layer: Introduced a unified auth interface that wrapped Clerk’s hooks. Zero behavior change, but now all auth access went through our abstraction.
- Backend migration: Set up Better-Auth server-side, migrated our user and organization data, and pointed our abstraction layer at the new backend.
- Frontend component swap: Replaced Clerk’s hosted components with our own UI built on Better-Auth primitives. This gave us the customization we wanted.
- Cleanup: Removed Clerk dependencies, deleted dead code, and updated documentation.
Each stage was a separate PR, reviewed and deployed independently. The entire migration—from proof of concept to Clerk fully removed—took about two weeks of calendar time, with actual developer effort measured in days rather than weeks. As an added bonus, we ended up with a nice abstraction layer around our auth system to avoid any future lock-in.
Post-migration: validation and monitoring
Don’t declare victory too early. After the migration is complete, maintain heightened monitoring for auth-related errors, user complaints, and edge cases you might have missed. Keep the old vendor’s documentation and your migration notes accessible in case you need to debug issues that surface later.
Target output: monitoring dashboard and runbook — set up alerts for authentication failures, session issues, and any vendor-specific error codes. Document the migration decisions and any known limitations of the new system.
Conclusion
The playbook is simple: understand, research, validate, implement incrementally. What makes it powerful is how agentic tools compress the effort at each stage. Tasks that once required days of manual code archaeology now take minutes of conversation with your codebase. Migrations that seemed too risky to attempt become routine maintenance.
The switching cost moat that SaaS vendors relied on is evaporating. Use that to your advantage—don’t stay locked into tools that no longer serve you just because migration used to be hard. With the right approach, tools, and mindset, it’s not possible to accomplish the kind of refactors that would once have languished on the technical debt backlog, all without disrupting the roadmap.